Physics Lournal
Powered by 🌱Roam GardenQiskit: Intro to Linear Algebra
Linear Algebra is the lingua franca of Quantum Computation.
Understanding of the basic mathematical concepts that it contains, are necessary to build and analyze the structures of quantum computation.
Vectors and Vector spaces.
At the outset, the fundamental quantity in quantum computation is the vector.
A vector , is defined as elements of a set known as a Vector Space.
Example of a vector quantity: Velocity: The rate at which a position is changing over time.
.
Velocity: The rate at which a position is changing over time.
You can conceptualize a vector geometrically as something having magnitude and direction, for instance a vector with x and y components , more generally
Within quantum computing, we often work with state vectors, vectors that represent a specific point in space that corresponds to some state in a quantum system, which can be visualized via a bloch sphere:
This particular vector state corresponds to an even superposition between and .
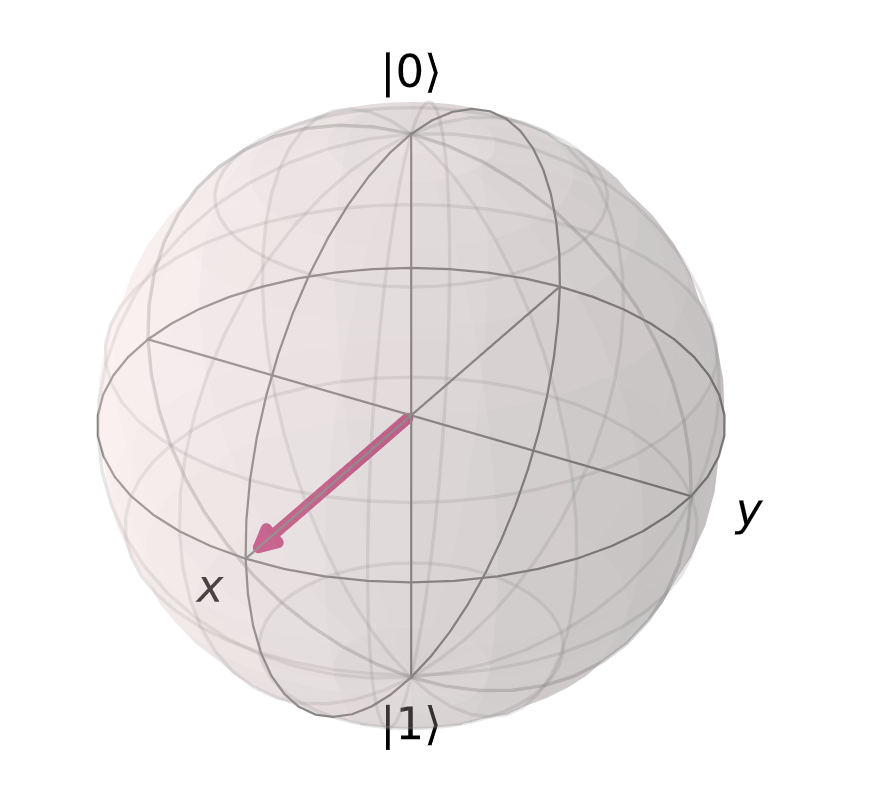
Vectors can rotate (around the center) to any point on the surface of the sphere, and each point represents a unique state of some quantum system.
In order to completely define vectors, we must define vector space:
A vector space over a field , is a set of vectors, where two conditions hold:
Vector addition of two vectors , will yield a third vector , which is also in .
Scalar multiplication between and some , written , is also contained in .
A field, in this context, can be thought of as some set of numbers, with the property that if , then aand b can be added, subtracted, multiplied and divided.
To clarify this, we will do an example, demonstrating the set over a field is a vector space, meaning:
, is also contained in .
This is true because the sum of two real numbers is also a real number, meaning both new vector components are real numbers, and so they must reside in .
Sidenote: A field in is written as , because it's a plane.
We also state that:
Scaling a vector.
Matrices and Matrix operations.
Another fundamental structure is that of the matrix, which can transform vectors into other vectors: .
Matrices can be represented as arrays of numbers:
A matrix can be applied to vectors, via matrix multiplication.
Generally, we take the first row of the first matrix, and multiply each element by its corresponding element in the column of the second matrix.
The sum of these elements, is the first element, in the first row of the new matrix. To fill the rest of the row, we take the first row of the first matrix by the rest of the columns of the second matrix exhaustively.
Then, we take the second row of the first matrix, and repeat the process for each column of the second matrix, until we've used all rows of the first matrix.
In order to carry out quantum computations, we take a quantum state vector, and manipulate it by applying a matrix to it. A vector is simply a matrix that only has one column. To carry out this multiplication, we carry out the above procedure. We manipulate qubits by applying sequences of quantum gates, which can be expressed as matrices of elements that alter the states of qubits, such as the Pauli-X gate:
.
The Pauli-X gate manipulates single qubits, and is the quantum equivalent of the not gate in classical computation, and is represented by the Pauli-X matrix: .
It flips the computational basis states, which are written as column vectors:
When we apply the Pauli-X matrix to the vectors:
Within quantum computation, we tend two encounter two types of matrices, Hermitian and Unitary matrices. The former is more related to Quantum Mechanics, but still has some relevance, whereas the latter is the bread and butter of quantum computation.
A Hermitian matrix is a matrix is that is equivalent to its Conjugate Transpose denoted , which means if you flip the signs of the imaginary components of the matrix, and then reflect these components over the top left diagonal, the resulting matrix will be the one you started with:
A Unitary matrix is similar, in that the inverse matrix is equal to the conjugate transpose.
The inverse of some matrix A, denoted , is a matrix such that: , where is the identity matrix.
The identity matrix has 1's along the top left diagonal, and 0's elsewhere.
When matrices grow beyond 2x2, calculating inverses is tedious, and is usually left to computers, but for a 2x2 matrix, we define the inverse as:
, where is the determinant of the matrix. In this 2x2 case, .
Calculating inverses is rarely important, since Unitary matrices inverses are given by the conjugate transpote.
The Pauli-Y matrix, for instance, is Hermitian, and unitary, meaning it is it's own inverse:
The basic idea is that evolving a quantum state via the application of a unitary matrix preserve the magnitude of the quantum state.
Spanning Sets, Linear Dependence and Bases
Here, we will take a look at the construction of vector spaces: Consider some vector space . We say that some set of vectors of spans some subset of the vector space (subspace), expressed by , if we can write any vector in the subspace, as a Linear Combination of the other vectors in the space.
This subset notation indicates that there are elements of that are not within .
A linear combination of some set of vectors, in a space over a field , is arbitrarily defined as the sum of said vectors, which will also be a vector:
, where each is some element of . If we have a set of vectors spanning some space, any other vector in that space, can be described by those other vectors.
A set of vectors is linearly dependent if there exist corresponding coefficients for each vector , such that:
, where at least one of the coefficients is non-zero. For example if we have , and some coefficients , such that the linear combination is 0.
Since there's a vector with a non-zero coefficient (a non-zero scalar applied to the basis vector), we choose that term, :
If is the only non-zero coefficient, then has been written as the null vector, meaning the set is linearly dependent. Otherwise, would be described as some element of the combination of non-zero vectors above. To prove the converse, we assume some vector in the subspace that can be written as a linear combination of other vectors:
, where is an index that spans the a subset of the subspace.
From this we get:
Essentially, for all vectors that are not included in the subset, we set their coefficients, indexed by q, to 0, thus:
If we have some vectors, , with the following respective components: , , , we can write as a combination of the components of like so: , ,